Introducción
Graphql es un lenguaje de consultas que provee una completa descripción de los datos de tu API, permitiendo al cliente recuperar solo los datos que necesita. Esto permite resolver algunos de los problemas más comunes como por ejemplo obtener menos datos de los que la aplicación necesita (underfetching) por lo que obliga al cliente realizar una segunda consulta al servidor, o recuperar más información del requerido (overfetching) por lo que los datos superfluos se descartan.
En este tutorial vamos a crear un API Graphql en que cual integraremos Flask y Ariadne. Flask es un ligero framework para desarrollo de aplicaciones web, diseñado para comenzar rápido y fácil, por lo que se ha convertido en uno de los frameworks Python más populares. Ariadne es un framework schema-first que permite definir APIs Graphql en Python y fácil de integrar con Flask.
Consideraciones
Este tutorial es completamente práctico, por lo que no voy a ahondar en conceptos teóricos por lo que se requiere tener algunas nociones sobre desarrollo en Python, Flask, Graphql (tipos de datos, queries, mutaciones, etc).
Proyecto
El proyecto consiste en un API Graphql para guardar, consultar, modificar y eliminar datos sobre autores y libros. Estableceremos una relación "one to many" de forma que un autor puede tener muchos libros, y un libro pertenece a un autor. Generaremos las queries de forma que al consultar los autores podamos acceder a los libros que tienen y, al consultar los libros poder ver los autores al que pertenecen. Las mutations nos permitirán añadir autores y libros, actualizarlos y eliminarlos.
Instalación
Comencemos creando el directorio del proyecto, yo lo llamé tutorial-flask-ariadne. Dentro de esta carpeta definimos un entorno virtual, para ello abre la consola e ingresa el siguiente comando python -m venv venv. Para activar el entorno escribe venv\Scripts\activate.
Instalamos Flask y Ariadne con el siguiente comando.
pip install -U flask ariadne
Seguimos con la instalación de flask-sqlalchemy, flask-marshmallow y sqlalchemy-marshmallow.
pip install -U flask-sqlalchemy flask-marshmallow marshmallow-sqlalchemy
Para poder conectarnos con nuestra base de datos necesitamos un driver. Lo instalamos como sigue python -m pip install PyMySQL.
Finalmente instalamos python-dotenv que nos permitirá leer nuestras variables de entorno.
Base de datos
Abre tu gestor de base de datos y crea una para nuestra app. Yo lo llamé tutorial_flask_ariadne. En la raíz del proyecto añade un fichero .env y define las siguientes variables de entorno.
USER="root"
PASSWORD=
PORT=3306
DATABASE="tutorial_flask_ariadne"
HOST="localhost"
Flask y Ariadne
A continuación integramos flask con ariadne para crear un servidor graphql. En la raíz de tu proyecto añade un fichero main.py y agrega el siguiente código.
from ariadne import QueryType, graphql_sync, make_executable_schema
from ariadne.constants import PLAYGROUND_HTML
from flask import Flask, request, jsonify
type_defs = """
type Query {
hello: String!
}
"""
query = QueryType()
@query.field("hello")
def resolve_hello(_, info):
request = info.context
user_agent = request.headers.get("User-Agent", "Guest")
return "Hello, %s!" % user_agent
schema = make_executable_schema(type_defs, query)
app = Flask(__name__)
@app.route("/graphql", methods=["GET"])
def graphql_playground():
return PLAYGROUND_HTML, 200
@app.route("/graphql", methods=["POST"])
def graphql_server():
data = request.get_json()
success, result = graphql_sync(
schema,
data,
context_value=request,
debug=app.debug
)
status_code = 200 if success else 400
return jsonify(result), status_code
if __name__ == "__main__":
app.run(debug=True)
Este código lo tomamos de la documentación oficial de Ariadne. Lo que podemos destacar son los dos endpoint principales. El primero captura una petición GET que nos da acceso al playground en el cual podremos testear nuestra API Graphql. El segundo captura las peticiones POST el cual se encarga de llevar a cabo nuestras queries y mutations.
También podemos ver una variable type_defs en el cual definiremos nuestra queries , mutations, types, etc. En este caso se define una sola consulta hello que retorna un string. La función resolve_hello es la que se encarga de resolver esta Query; en este caso retorna un saludo "Hello" y la información del navegador.
Con el comando flask --app main run puedes correr el servidor de desarrollo. Ingresa al endpoint 127.0.0.1:5000/graphql para ver el playground.

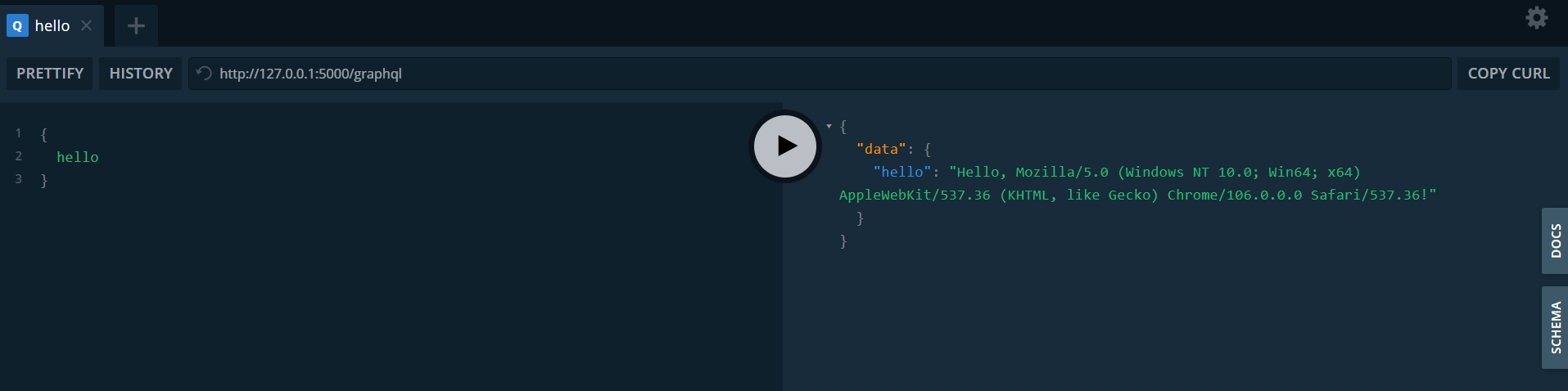
A continuación seguiremos con la definición de los modelos y los esquemas de serialización.
Modelos
Comencemos creando un nuevo directorio models para los modelos. Dentro de este directorio añade un fichero __init__.py. Este fichero le indica al interprete de Python que el directorio es un paquete en el cual estarán nuestros módulos. Usaremos este fichero para inicializar SQLAlchemy y Marshmallow.
from flask_sqlalchemy import SQLAlchemy
from flask_marshmallow import Marshmallow
db = SQLAlchemy()
ma = Marshmallow()
Ahora creamos los archivos author.py y book.py para los modelos autor y libro respectivamente. Definiremos el modelo author primero. Dentro de este fichero inserta el siguiente código.
from models import db
class Author (db.Model):
__tablename__= "authors"
id= db.Column(db.Integer, primary_key=True)
name= db.Column(db.String(255))
lastname= db.Column(db.String(255))
created_at= db.Column(db.DateTime, server_default=db.func.now())
updated_at= db.Column(db.DateTime, server_default=db.func.now(), onupdate=db.func.now())
books= db.relationship("Book", backref="author", cascade="all, delete-orphan")
Lo primero que podemos ver es que importamos db que es la instancia de SQLAlchamy() que definimos anteriormente. Seguimos con la declaración de la clase Author, los campos y la relación. Con la directiva __tablename__ indicamos el nombre de la tabla. Los campos id, name y lastname se explican por sí mismos. Los campos created_at y updated_at son timestamps que registran la fecha en que un registro es creado y actualizado.
La última línea define la relación. El primer parámetro indica el modelo al cual se vincula, en este caso Book. El parámetro backref agrega una referencia en el modelo Book que se comportará como la columna que le dará acceso al autor del libro. El parámetro cascade significa de que si el registro de la tabla padre (Author) es borrado, todos los registros relacionados en la tabla hija (Book) serán eliminados también.
Continuamos con el fichero book.py.
from models import db
class Book (db.Model):
__tablename__="books"
id= db.Column(db.Integer, primary_key=True)
title= db.Column(db.String(255))
created_at= db.Column(db.DateTime, server_default=db.func.now())
updated_at= db.Column(db.DateTime, server_default=db.func.now(), onupdate=db.func.now())
author_id = db.Column(db.Integer, db.ForeignKey("authors.id"))
La definición de este modelo no difiere del anterior. Tenemos un campo id, title para el título del libro y los campos para los timestamps. Lo que podemos destacar es el campo author_id que es la que usamos como llave foránea para vincular esta tabla con la tabla autor, usando su id. De esta manera queda definida la relación "one to many" entre las tablas.
Seguimos con la definición de los esquemas para serialización/deserialización.
Esquemas
Para mantener esto simple, definiremos los ficheros para los esquemas dentro del mismo directorio models. Crea dos archivos authorSchema.py y bookSchema.py. Primero authorSchema.py.
from models import ma
from models.author import Author
class AuthorSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = Author
include_relationships = True
books= ma.List(ma.Nested("BookSchema", exclude=("author",)))
Primero importamos la instancia de Marshmallow , ma. En la segunda línea indicamos que del módulo models.author queremos importar la clase Author. Definimos la clase AuthorSchema y le pasamos como parámetro ma.SQLAlchemyAuthorSchema. Con el atributo model vinculamos este esquema con el modelo Author. include_relationships = True indica que nos incluya las relaciones declaradas en el modelo.
La línea books= ma.List(ma.Nested("BookSchema", exclude=("author",))) indica que el atributo books es una arreglo de libros, el cual tiene un esquema anidado (BookSchema). Es importante destacar la opción exclude. En él declaramos que excluya este campo, para evitar recursión infinita.
Continuamos con el esquema para los libros. Abre el fichero bookSchema.py y añade.
from models import ma
from models.book import Book
class BookSchema(ma.SQLAlchemyAutoSchema):
class Meta:
model = Book
include_fk = True
author= ma.Nested("AuthorSchema", only=("id", "name", "lastname"))
Como puedes ver no difiere mucho del esquema anterior. Mediante el atributo model vinculamos este esquema con el modelo Book. Con include_fk indicamos que nos incluya la llave foránea.
La línea author= ma.Nested("AuthorSchema", only=("id", "name", "lastname")) indica que el atributo author tiene un esquema anidado AuthorSchema para acceder a los datos del autor. Con la opción only señalamos los campos que queremos recuperar de AuthorSchema. Al igual que la opción exclude de AuthorSchema, nos sirve para evitar recursión infinita.
Con esto finalizamos con los modelos y los esquemas. Continuamos con la conexión a la base de datos.
Base de datos
Para establecer la conexión primero importamos import os para interactuar con las funciones del sistema operativo. Lo utilizaremos para obtener los valores de las variables de entorno que definimos en el fichero .env.
También importamos los módulos del directorio models.
from models import db, ma
from models.author import Author
from models.book import Book
from models.authorSchema import AuthorSchema
from models.bookSchema import BookSchema
Justo después de definir app=Flask(__name__) agregamos la conexión.
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql+pymysql://{}@{}:{}/{}".format(os.environ.get("USER"), os.environ.get("HOST"), os.environ.get("PORT"), os.environ.get("DATABASE"))
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db.init_app(app)
ma.init_app(app)
with app.app_context():
db.create_all()
La opción app.config["SQLALCHEMY_DATABASE_URI"] recibe un string con los valores de USER, PORT y DATABASE.
Luego inicializamos las extensiones de SQLAlchemy y Marshmallow, en ese orden. Finalmente la función db.create_all() crea las tablas en nuestra base de datos con la estructura que definimos en los modelos.
Reinicia el servidor de desarrollo para que los cambios tengan efecto.
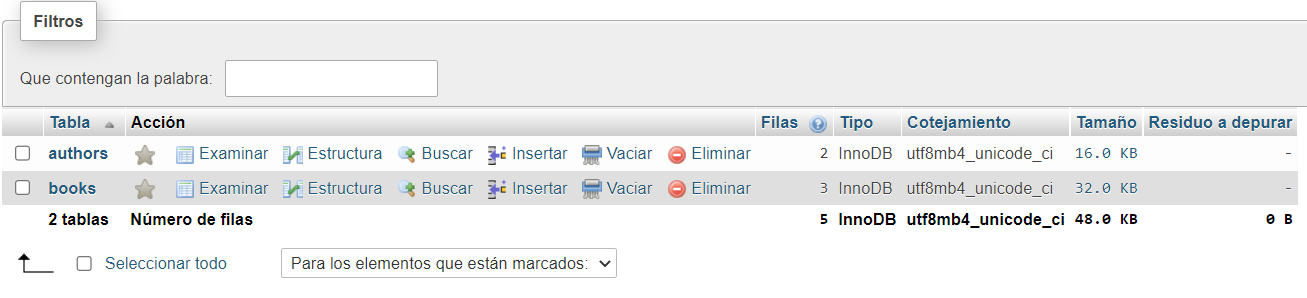
Finalizamos con la conexión. Seguimos con la definición de las queries, mutations, object types y los resolvers.
Object types, queries y mutations
Las queries y mutations los vamos a definir en un paquete propio. Crea un directorio schemas y añade el correspondiente fichero __init__.py. Crea un archivo type_defs.py. Comenzaremos definiendo los object types.
Object types
Abre el fichero type_defs.py y inserta el siguiente código.
from ariadne import gql, ScalarType
from datetime import datetime
datetime_scalar = ScalarType("Datetime")
@datetime_scalar.serializer
def datetime_serializer(value):
return datetime.strptime(value,"%Y-%m-%dT%H:%M:%S")
type_defs = gql("""
scalar Datetime
type Author {
id: ID
name: String
lastname: String
books: [Book]
created_at: Datetime
updated_at: Datetime
}
type Book {
id: ID
title: String
author: Author!
created_at: Datetime
updated_at: Datetime
}
""")
La función gql nos provee una forma de validar los esquemas que definimos. ScalarType nos permite definir scalar types personalizados. Lo usaremos para definir el scalar Datetime para manejar fechas. La función datetime_serializer le dice a Ariadne el formato que queremos para las fechas.
En la variable type_defs que declaramos definimos los tipos Author y Book. Lo que podemos destacar en el tipo Author es el campo books, en él indicamos que retorna un arreglo de libros y puede ser nulo. En el tipo Book el campo author debe retornar un Author y no puede ser nulo.
Queries
Justo a continuación del tipo Book añadimos.
type_defs = gql("""
scalar Datetime
type Author {
id: ID
name: String
lastname: String
books: [Book]
created_at: Datetime
updated_at: Datetime
}
type Book {
id: ID
title: String
author: Author!
created_at: Datetime
updated_at: Datetime
}
type Query {
author(id: ID!): Author!
authors: [Author]
book(id: ID!): Book!
books: [Book]
}
""")
Las queries author(id: ID!): Author! y book(id: ID!): Book! retornan un objeto de tipo Author y Book respectivamente. Las queries authors: [Author] y books: [Book] retornan un arreglo de objetos de tipo Author y Book.
Mutations
Continuamos con las mutaciones.
type_defs = gql("""
scalar Datetime
type Author {
id: ID
name: String
lastname: String
books: [Book]
created_at: Datetime
updated_at: Datetime
}
type Book {
id: ID
title: String
author: Author!
created_at: Datetime
updated_at: Datetime
}
type Query {
author(id: ID!): Author!
authors: [Author]
book(id: ID!): Book!
books: [Book]
}
type Mutation {
addAuthor(name: String!, lastname: String!): Author!
addBook(title: String!, author_id: ID): Book!
updateAuthor(id: ID!, name: String!, lastname: String!): Author!
updateBook(id: ID!, title: String!): Book!
deleteAuthor(id: ID!): Author!
deleteBook(id: ID!): Book!
}
""")
Las mutaciones addAuthor y addBook nos permiten añadir un autor y un libro respectivamente. updateAuthor y updateBook nos permiten actualizarlos y finalmente tenemos dos mutaciones más deleteAuthor y deleteBook para eliminarlos.
Finalmente debemos importar los tipos definidos en type_defs y el scalar personalizado datetime_scalar al fichero main.py
from schemas.type_defs import type_defs, datetime_scalar
Lo pasamos a la función make_executable_schema.
schema = make_executable_schema(type_defs, [query, datetime_scalar])
Resolvers
Antes de comenzar con los resolvers creamos las instancias de los esquemas que vamos a utilizar.
author_schema = AuthorSchema()
authors_schema = AuthorSchema(many=True)
book_schema = BookSchema()
books_schema = BookSchema(many=True)
Los esquemas author_schema y book_schema retornan un único objeto, mientras que los esquemas authors_schema y books_schema los usaremos para retornar un arreglo de objetos.
Ahora comenzamos con los resolvers para las consultas.
@query.field("authors")
def resolve_authors(_, info):
data = Author.query.all()
return authors_schema.dump(data)
@query.field("books")
def resolve_books(_, info):
data = Book.query.all()
return books_schema.dump(data)
@query.field("author")
def resolve_author(_, info, id):
data = Author.query.get(id)
return author_schema.dump(data)
@query.field("book")
def resolve_book(_, info, id):
data = Book.query.get(id)
return book_schema.dump(data)
El decorador @query.field() recibe un string con el nombre del query al que queremos vincular el resolver.
El resolver resolve_authors hace uso del modelo Author para recuperar todos los datos de la base de datos y los guarda en la variable data. Luego retornamos los datos serializado con authors_schema.dump.
El resolver para los libros hace lo mismo. El modelo Book recupera todos los registros y retorna los datos serializados con books_schema.dump.
El resolver resolve_author recibe un id. Mediante el modelo Author recuperamos el autor con ese id y lo guarda en data. Retornamos los datos serializados con author_schema.dump.
Los mismo para resolve_book. Recibe el id con el que el modelo Book obtiene el libro de la base de datos. Serializa los datos con book_schema.dump y los retorna.
Ahora continuamos con las mutaciones. Primero importamos las clase MutationType y pasamos la instancia a make_executable_schema.
from ariadne import QueryType, MutationType,graphql_sync, make_executable_schema
mutation = MutationType()
schema = make_executable_schema(type_defs, [query, mutation, datetime_scalar])
Ahora definimos los resolvers para las mutaciones.
@mutation.field("addAuthor")
def resolve_add_author(_, info, name, lastname):
author = Author(name=name, lastname=lastname)
db.session.add(author)
db.session.commit()
return author_schema.dump(author)
@mutation.field("addBook")
def resolve_add_book(_, info, title, author_id):
author = Author.query.get(author_id)
book = Book(title=title, author=author)
db.session.add(book)
db.session.commit()
return book_schema.dump(book)
@mutation.field("updateAuthor")
def resolve_update_author(_, info, id, name, lastname):
author = Author.query.get(id)
author.name = name
author.lastname = lastname
db.session.commit()
return author_schema.dump(author)
@mutation.field("updateBook")
def resolve_update_book(_, info, id, title):
book = Book.query.get(id)
book.title = title
db.session.commit()
return book_schema.dump(book)
@mutation.field("deleteAuthor")
def resolve_delete_author(_, info, id):
author = Author.query.get(id)
db.session.delete(author)
db.session.commit()
return author_schema.dump(author)
@mutation.field("deleteBook")
def resolve_delete_book(_, info, id):
book = Book.query.get(id)
book.author = None
db.session.delete(book)
db.session.commit()
return book_schema.dump(book)
El decorador @mutation.field() recibe un string con el nombre de la mutación al que queremos vincular el resolver.
resolve_add_author recibe name y lastname. Creamos una instancia del modelo Author, le pasamos los parámetros. Con db.session.add y db.session.commit añadimos el registro a la base de datos. Luego retornamos los datos del nuevo registro con author_schema.dump(author).
resolver_add_book es similar al anterior. Recibe title y author_id. Primero recuperamos el autor del libro por medio de Author.query.get(id) y lo guardamos en la variable author. Luego creamos una instancia del modelo Book y le pasamos el title y el author. Añadimos el registro y luego retornamos los datos del nuevo libro con book_schema.dump(book).
resolve_update_author recibe id, name y lastname. Con Author.query.get(id) recuperamos el autor y lo guardamos en author. Actualizamos los datos y luego con db.session.commit guardamos los cambios. Finalmente retornamos los datos del autor actualizado.
resolve_update_book recibe id y title. Obtenemos el libro con Book.query.get(id) y lo guardamos en la variable book. Actualizamos en título y con db.session.commit guardamos los cambio. Luego retornamos los datos del libro actualizado.
resolve_delete_author recibe un id. Obtenemos el autor que queremos eliminar con Author.query.get(id) y lo guardamos en la variable author. Por medio de db.session.delete(author) eliminamos el autor y guardamos los cambios con db.session.commit. Esto debe eliminar el autor y los libros que tiene. Retornamos los datos del autor eliminado.
resolve_delete_book recibe un id. Recuperamos el libro con Book.query.get(id) y lo guardamos en book. Antes de eliminar el libro debemos desvincularlo de su autor. Para ello establecemos a None el atributo book.author. Ahora sí, eliminamos el registro con db.session.delete(book). Esto debe eliminar el libro, pero no el autor. Finalmente retornamos los datos del libro eliminado.
Con esto finalizamos de construir el API Graphql, ahora es tiempo de ponerlo a prueba y ver su funcionalidad.
Probando el API Graphql
Comencemos reinicializando el servidor de desarrollo flask --app main run. Entra al endpoint 127.0.0.1:5000/graphql para ver el "playground".
Primer añadiremos algunos autores.
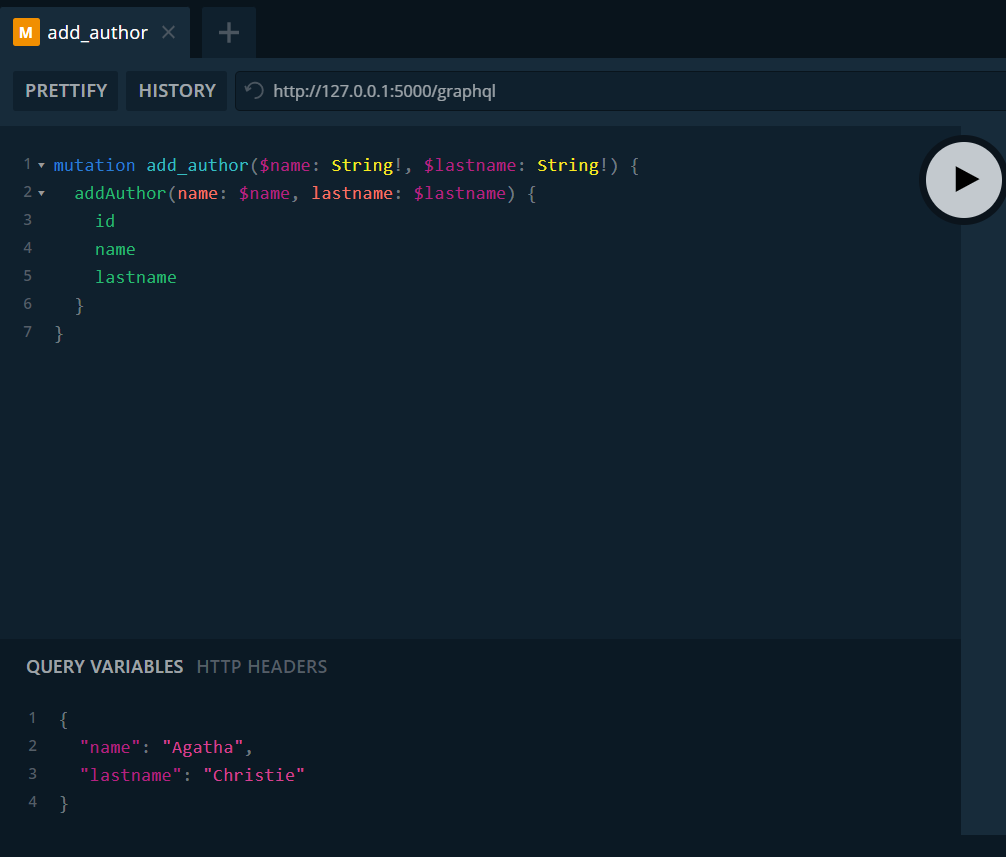
Observamos que definimos la mutación que queremos ejecutar, indicamos que recibe las variables $name y $lastname ambas de tipo String. En la parte inferior podemos ver la sección donde pasamos los valores a la mutación. Estoy insertando a "Agatha Christie". También voy a insertar a "Wilbur Smith". Podemos ver los registros en la tabla.
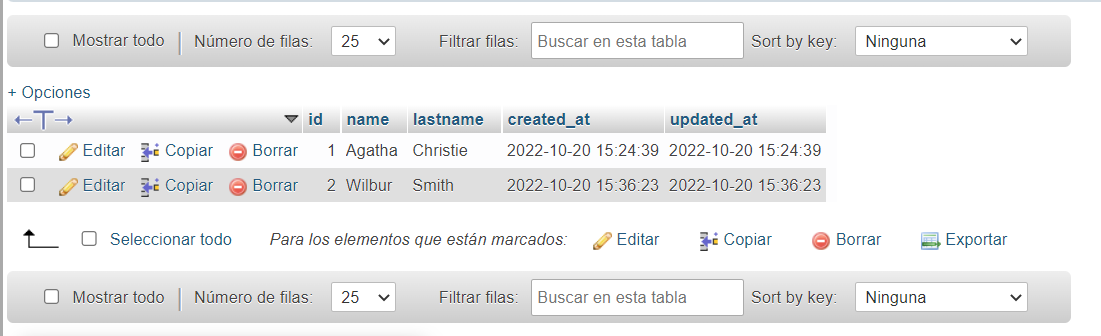
Excelente, ahora probemos insertar algunos libros de los autores.
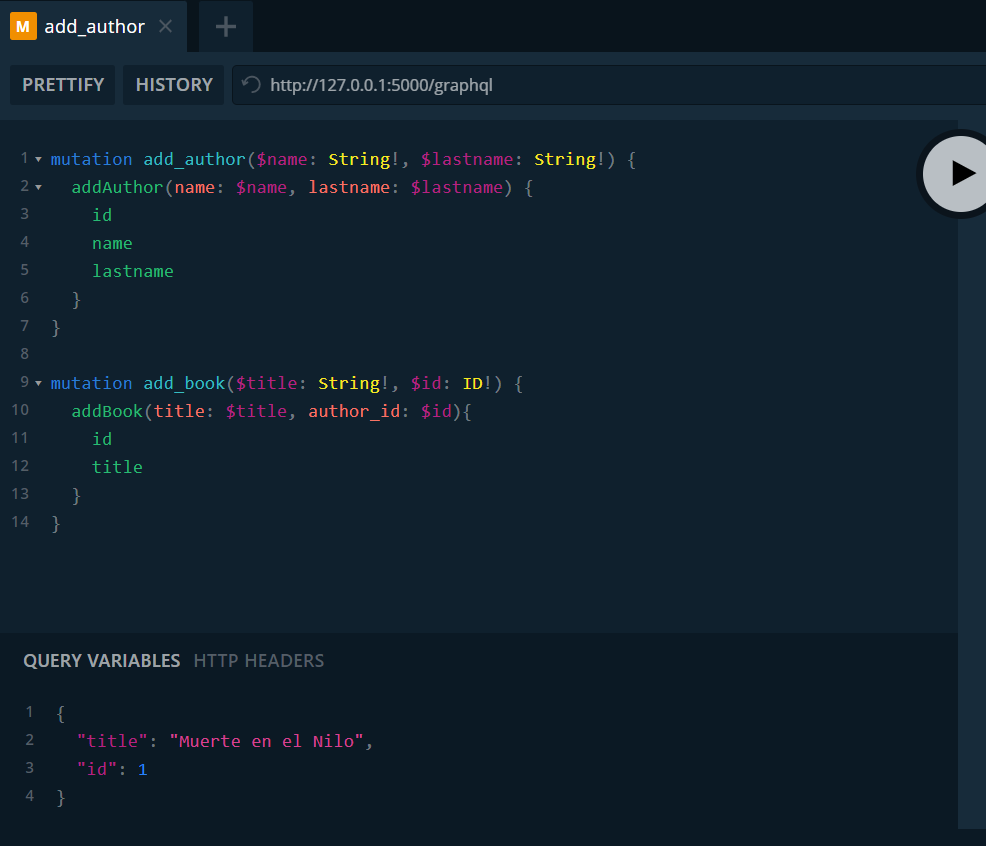
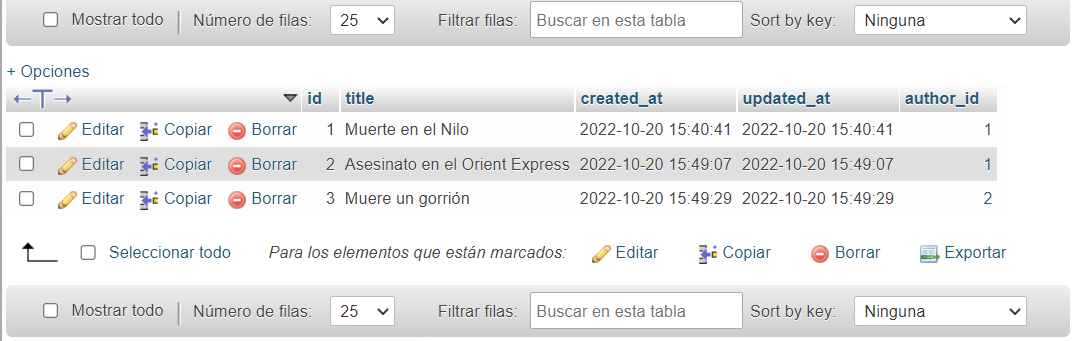
Definimos otra mutación para añadir un libro, e indicamos que recibe las variables $title de tipo String y $id de tipo ID. En la sección de variables pasamos el título del libro y el id del autor. En este caso "Muerte en el Nilo", que pertenece a "Agatha Christie". También voy a añadir "Asesinato en el Orient Express" de la misma autora y "Muere un gorrión" de "Wilbur Smith". Podemos ver los registros en la tabla.
Seguimos probando las mutaciones para actualizar datos del autor.
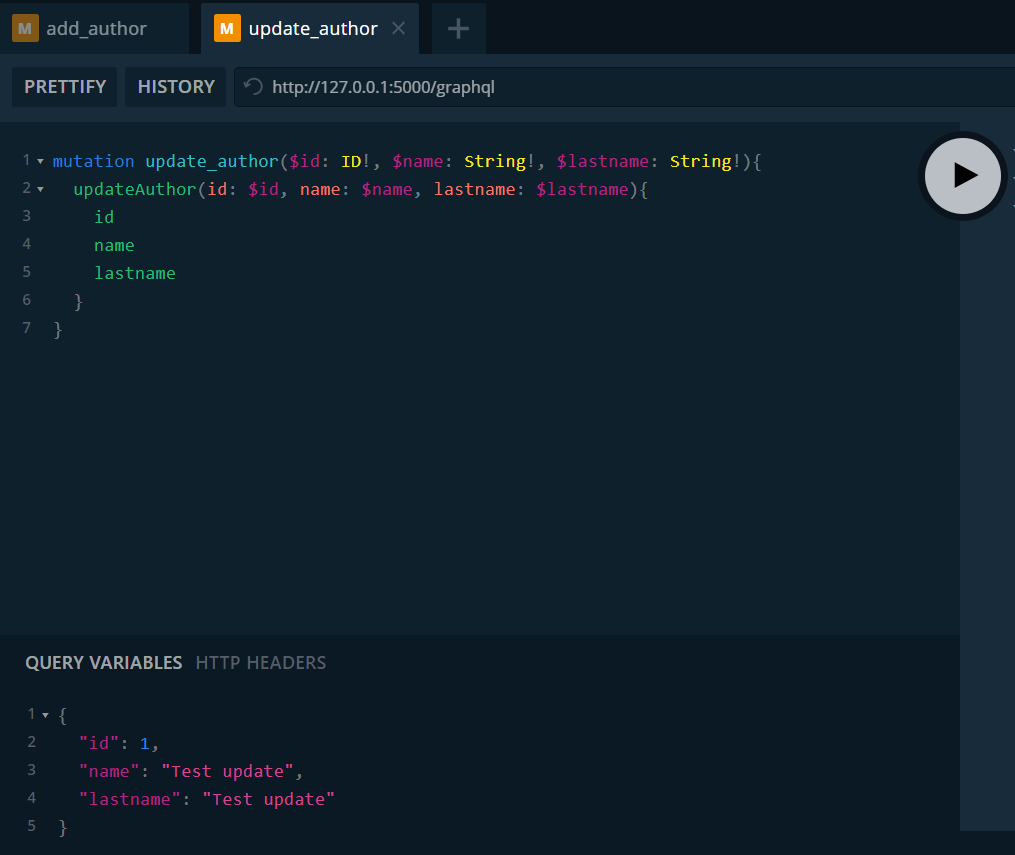
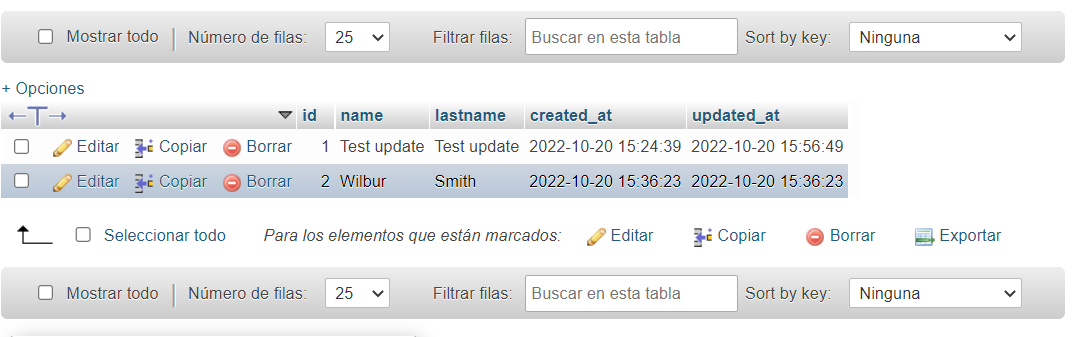
Al igual que en los ejemplos anteriores definimos la mutación que queremos y definimos las variables que recibe. En la sección de variables indicamos que queremos modificar los valores del autor con id 1. Paso cualquier valor ya que es solo para verificar la funcionalidad. Lo vemos en la tabla.
Todo bien hasta ahora, seguimos con la actualización de los libros.
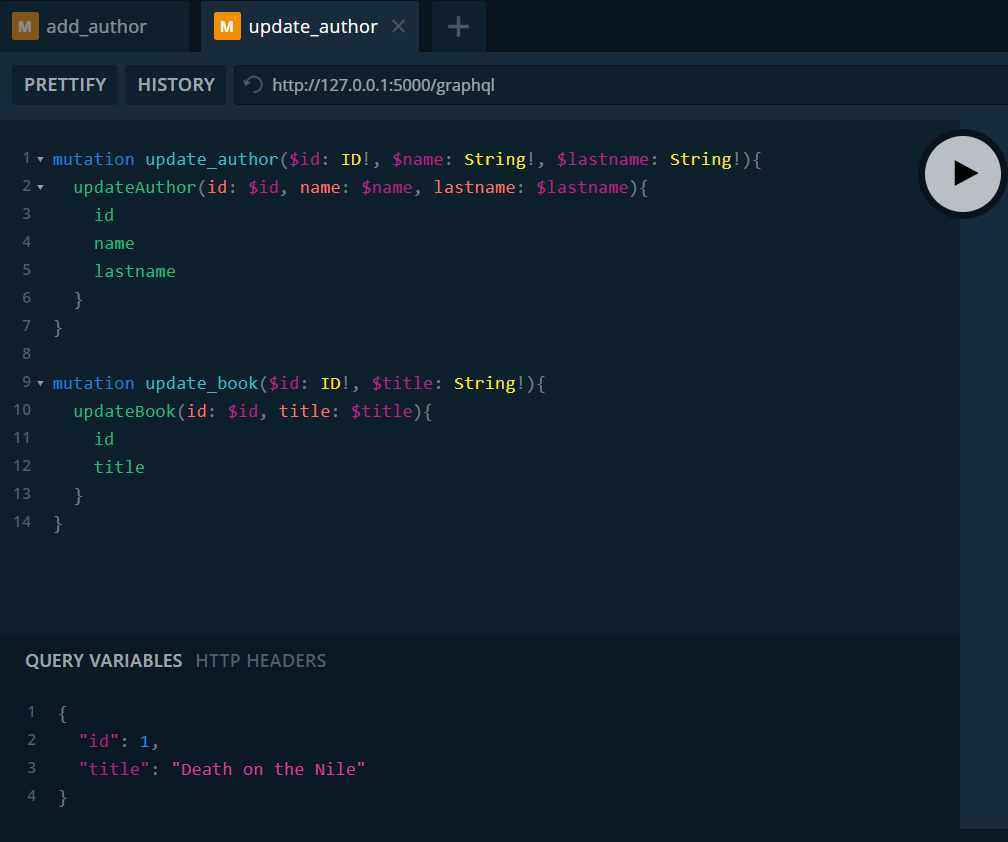
Estoy modificando el título del libro con id 1. En este caso es el mismo nombre pero en inglés. Lo vemos en la tabla.
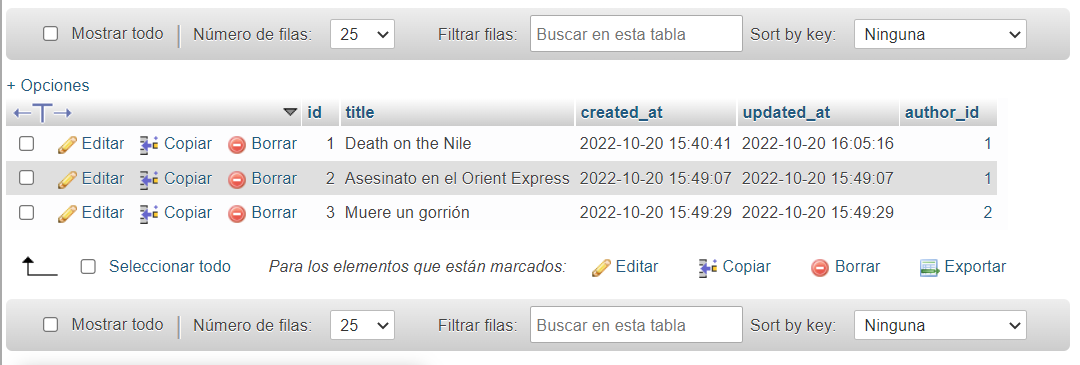
Antes de probar las mutaciones para eliminar datos, voy a proba las consultas. Empecemos recuperando los autores.
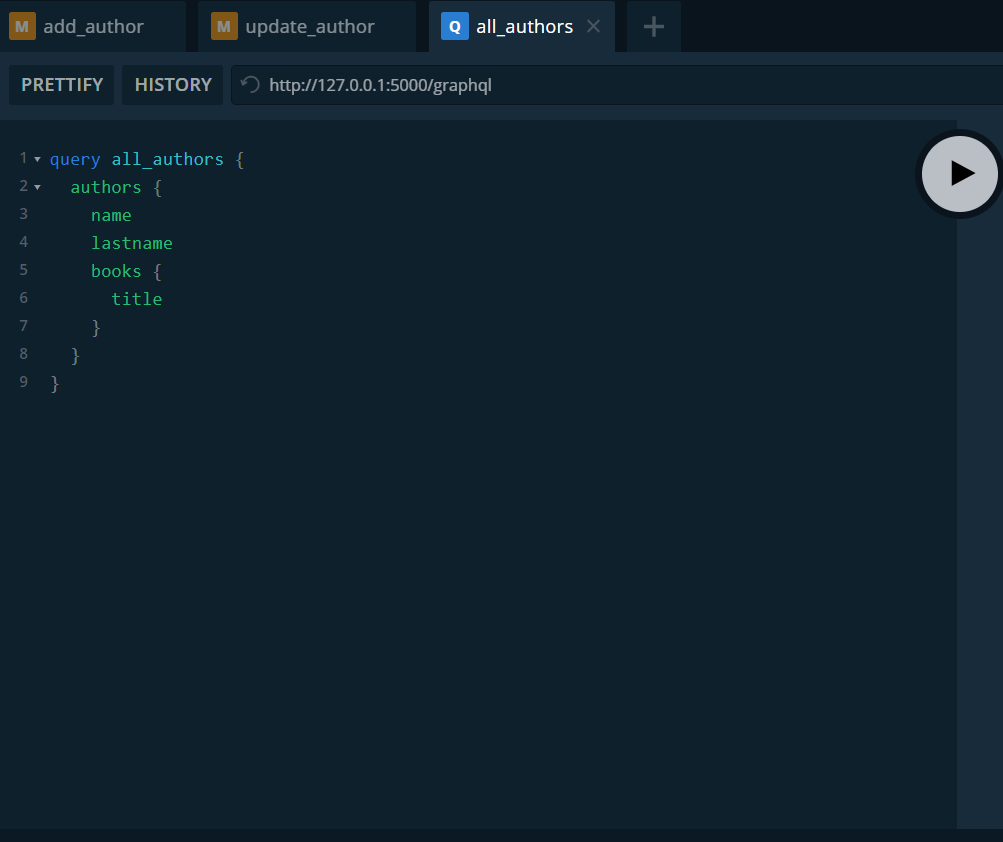
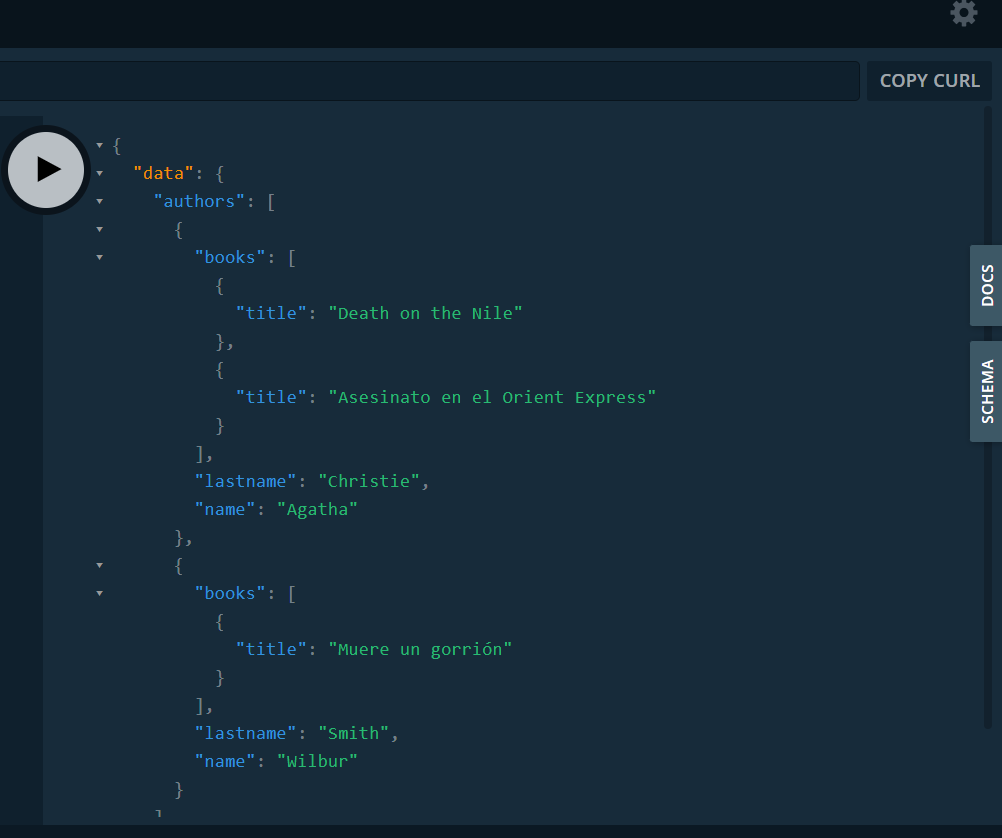
Definimos la consulta e indicamos que además de los datos del autor queremos ver los libros que tienen.
Ahora probamos la consulta de un autor por su id.
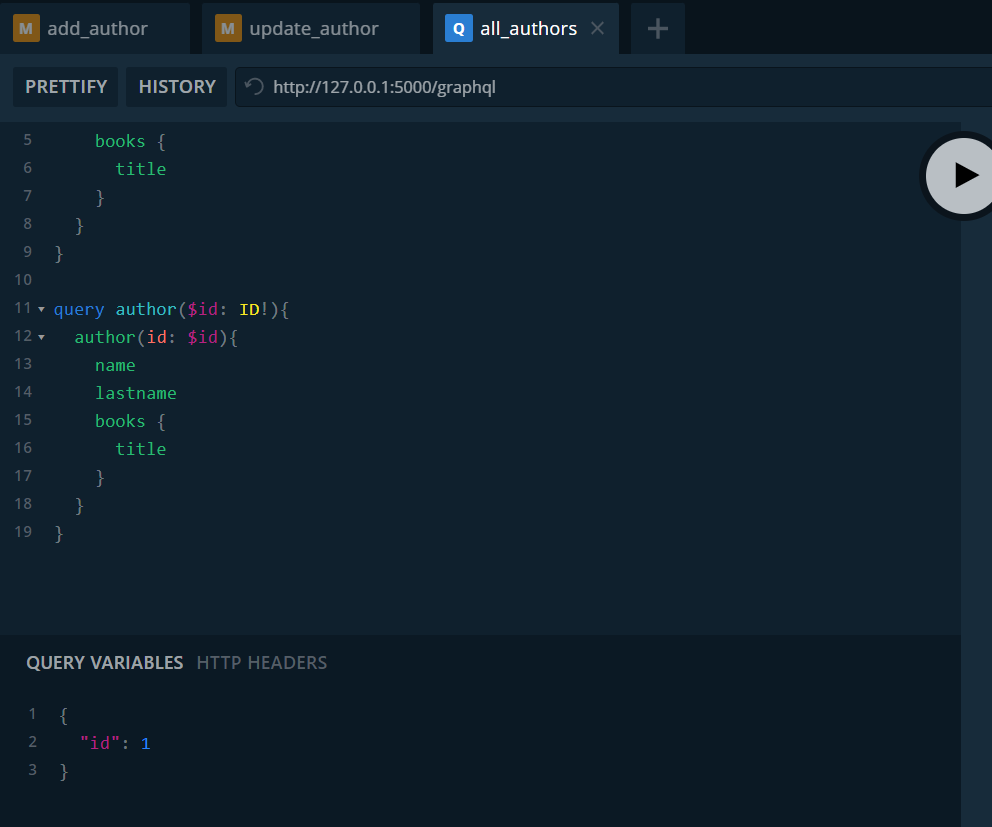
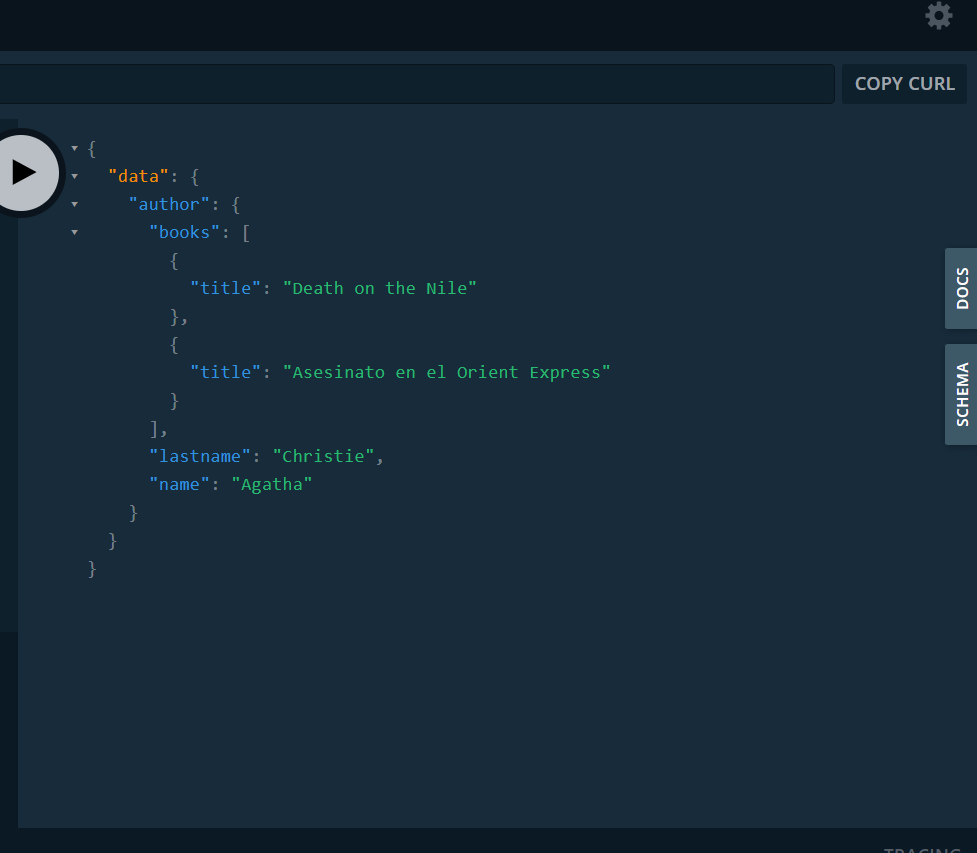
Definimos la consulta para obtener un autor y le pasamos el correspondiente id. Además de los datos del autor, recuperamos los títulos de sus libros.
Probamos la funcionalidad para obtener todos los libros.
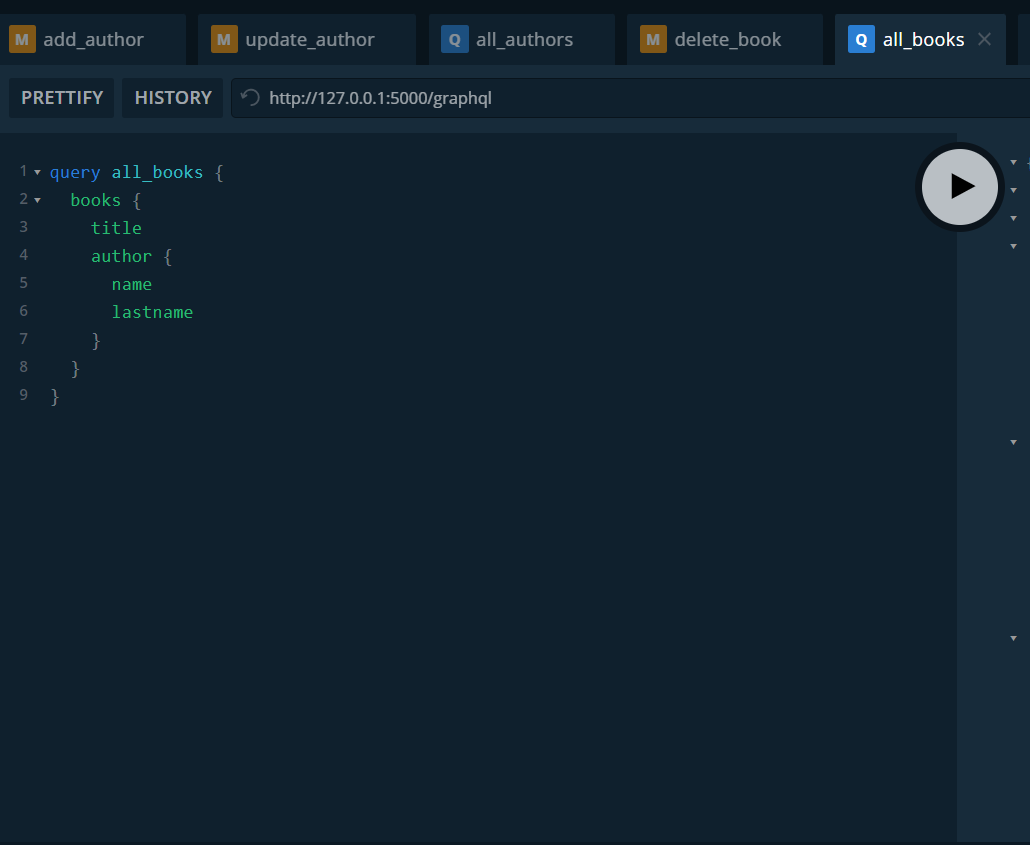
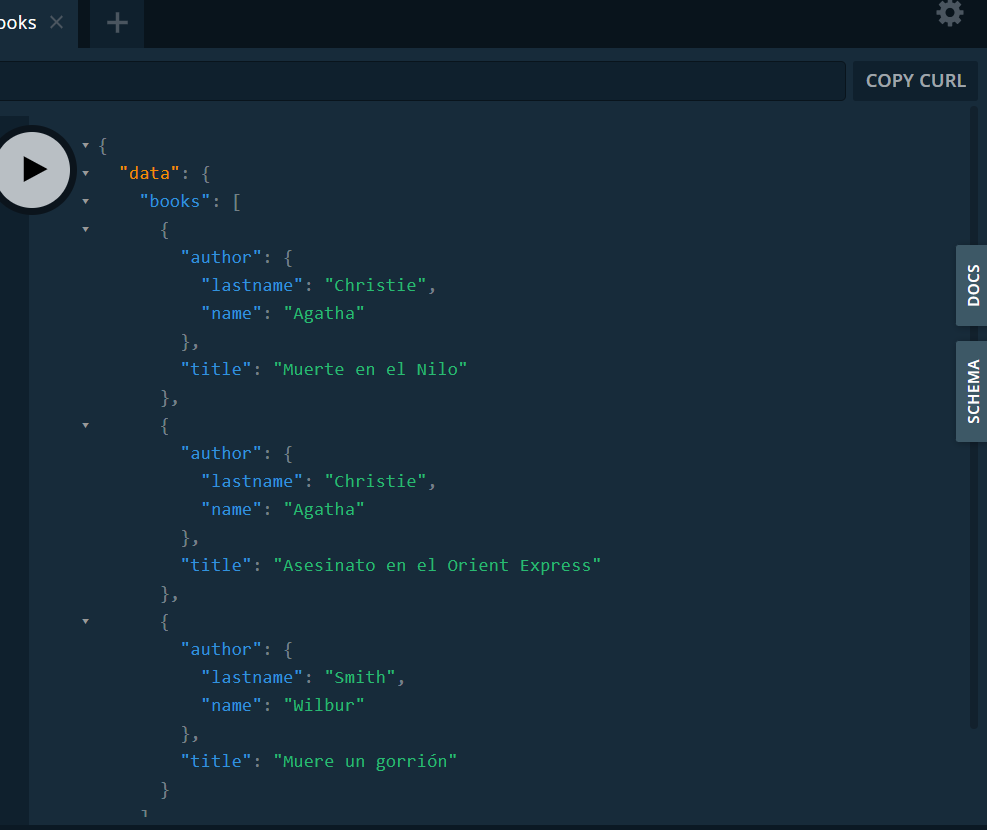
Además del título del libro obtenemos los datos del autor.
Ahora probamos obtener un libro por su id.
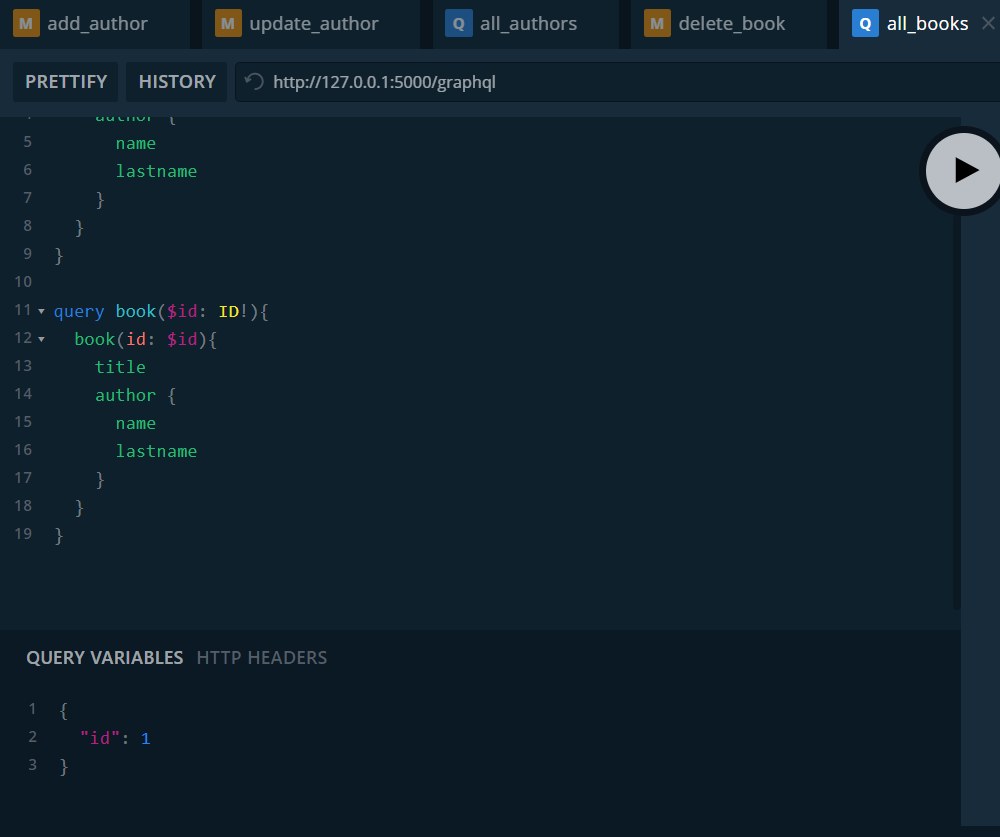
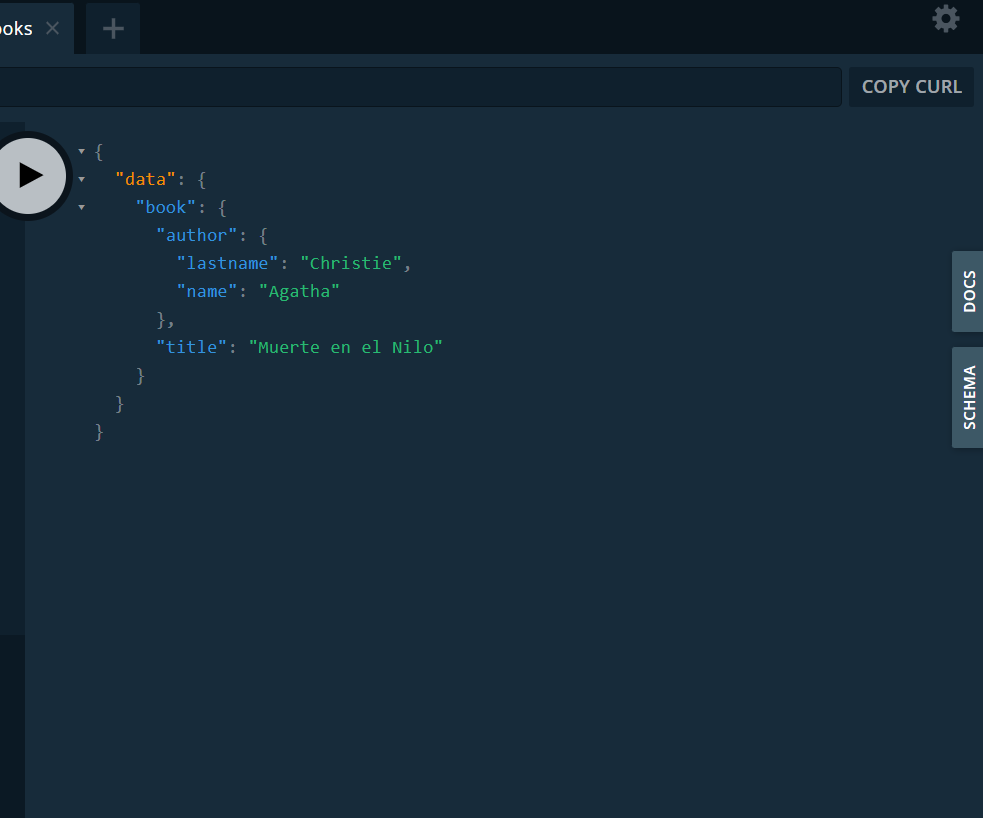
Recuperamos los datos del libro y además los datos del autor.
Nos toca probar las mutaciones para eliminar datos. Comencemos eliminando un libro.
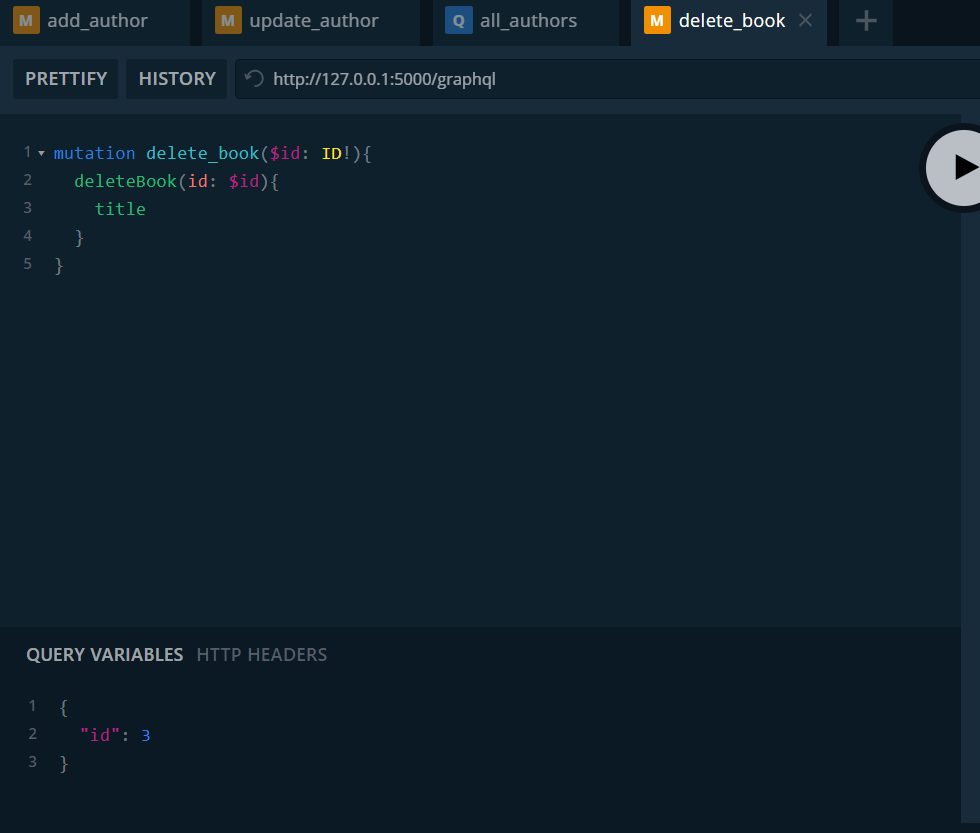
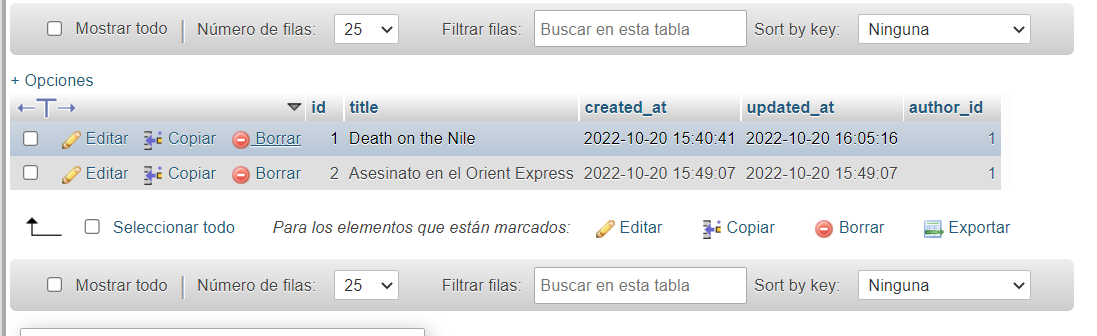
Definimos la mutación para eliminar un libro y le pasamos el id. Lo vemos en la tabla, eliminamos el libro con id 3. Recordemos que esta mutación no elimina el autor.
Ahora eliminamos un autor.
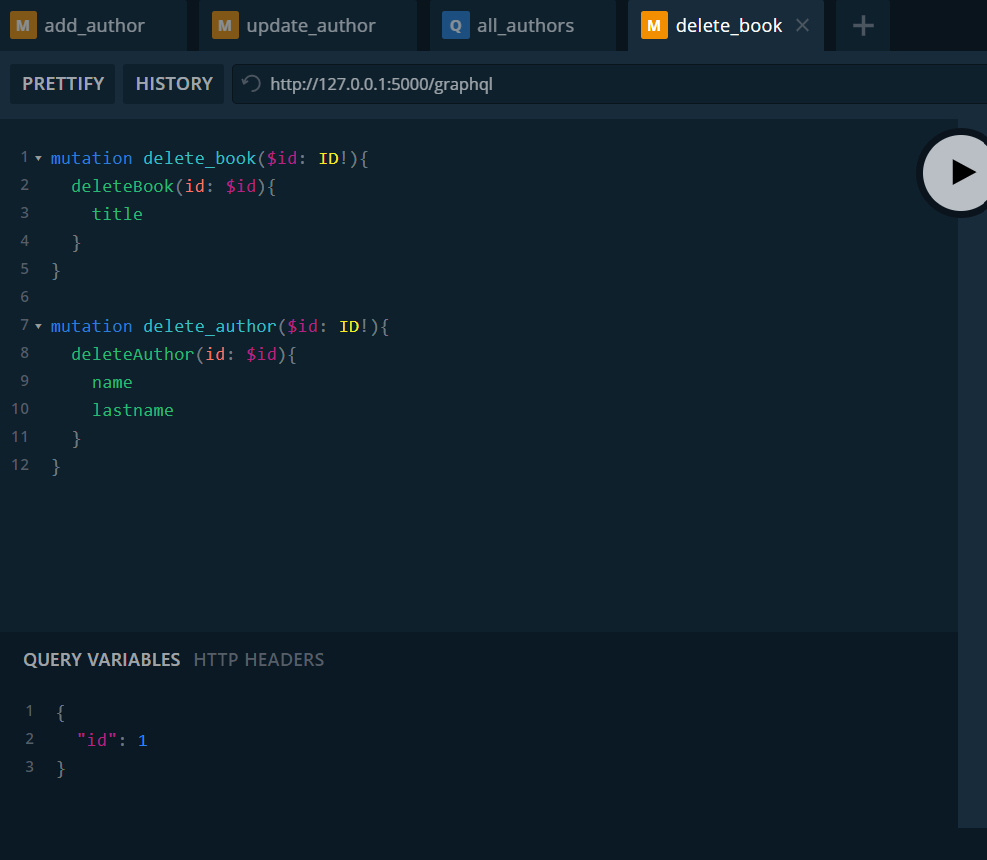
Definimos la mutación para eliminar un autor y pasamos el id. Lo vemos en las tablas.
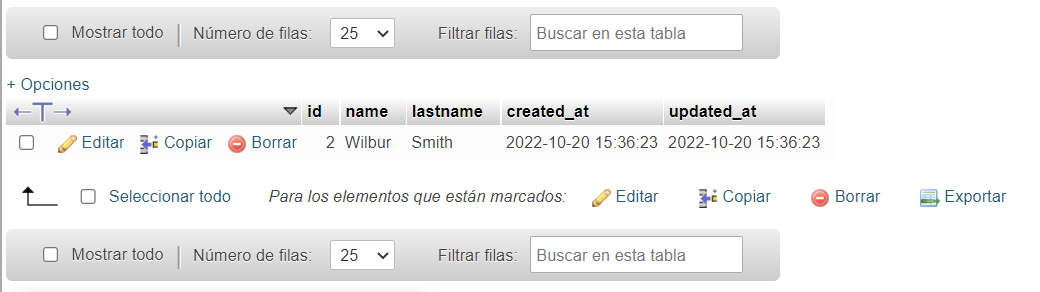
Aquí podemos observar que no solo elimina el autor, sino que también elimina los libros que le pertenecen, por lo que la tabla books queda vacía.
Excelente, hemos concluido con las pruebas y comprobamos que todas las funcionalidades se ejecutan correctamente.
Conclusión
Hemos finalizado con el proyecto. En este tutorial hemos repasado de manera práctica los principales conceptos para tener un API Graphql completamente funcional en python. Aprendimos a integrar Flask con Ariadne, y además, vimos como integrar Flask-SQLAlchemy con Flask-Marshmallow para generar tablas relacionales y poder serializar los datos.
Puedes encontrar proyecto completo en mi repositorio de GitHub haciendo clic AQUÍ.
Espero que lo hayas encontrado entretenido, instructivo y claro. Si tienes alguna duda, puedes hacérmelo saber en los comentarios. Pronto estaré subiendo más tutoriales.
Nos vemos en la próxima. Saludos!👋😊





